使用mapper接口
1.这个接口的全限定类名===对应的Mapper文件的namespace;
2.这个接口中的方法和Mapper文件中的SQL元素一一对应:
XML文件1
2
3
4
5
6
7
8
9
10
11
<!-- StudentMapper的全限定类名 -->
<mapper namespace="me.cscar.many2many.mapper.StudentMapper">
<insert id="save" useGeneratedKeys="true" keyProperty="id" keyColumn="id">
INSERT INTO student (name) VALUES (#{name} )
</insert>
</mapper>
测试类文件1
2
3
4SqlSession session = MybatisUtil.getSession();
StudentMapper studentMapper = session.getMapper(StudentMapper.class);
/* 通过传入StudentMapper.class获得全限定名,就是namespace
返回StudentMapper对象,调用save方法 */
mapper接口1
2void save(Student stu);
//方法名为id
动态SQL
if
set
where
switch
在多个中选择一个
foreach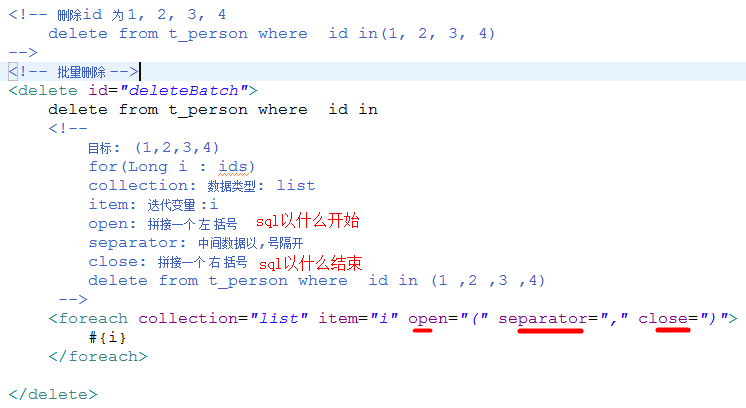
trim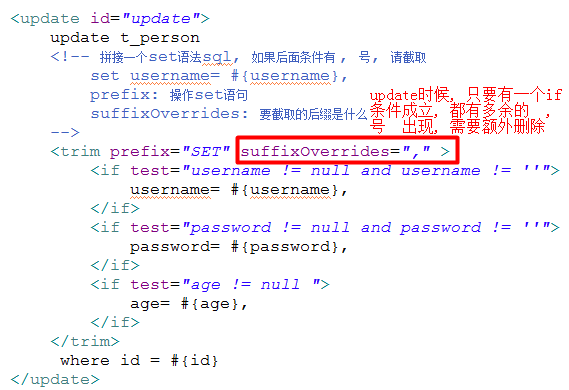
#{}和${}的区别
相同: #和$都可以从对象或者Map中获取参数值
不同:
使用#设置参数时候,先将参数转为?占位符,然后再赋值:使用PreparedStatement
使用$设置参数时,直接将参数拼接到sql中,使用Statement
使用$设置参数可能存在SQL注入隐患.
使用#设置参数,如果是字符串,会自动加上’’, 而$不会,它会原样输出
在一些情况下,比如排序,比如分组操作时候拼接参数时不应该拼接’’
总结:一般设置参数使用#,如果要拼接sql
比如 排序,分组等.使用 $ (因为他们是按照列名来排序和分组的)
使用@param设置多个参数
MyBatis在#{}中参数流程:
1.会去参数对象中,按照属性或者Map的key去查询;
2.如果找不到,尝试直接把方法的实际参数作为查询参数值
如果一定要在Mapper接口上的一个方法中添加多个参数,就一定要在每个参数前使用@Param标签.
原理:Mybatis在处理这些Mapper方法的时候,会自动的把这些参数包装成一个Map对象,@Param中的value就会作为这个Map的key,对应的参数值,就会作为这个Key的value;
原理:
mybatis自动把参数封装成map
对象关系
1.依赖关系:如果A对象离开了B对象,A对象就不能正常编译,则A对象依赖B对象.
2.关联关系:A对象依赖B对象,并且把B对象作为A对象的一个属性,则A和B是关联关系.(特殊的依赖关系)
3.聚合关系:表示整体和部分的关系,整体和部分之间可以相互独立存在,一定是有两个模块来分别管理整体和部分.
4.组合关系:强聚合关系,但是整体和部分不能独立存在,一定是在一个模块中同时管理整体和部分,生命周期必须相同.
5.泛化关系:其实就是继承关系.
关联关系划分
1.一对一:一个A对象属于一个B对象,一个B对象属于一个A对象.
2.一对多:一个A对象包含多个B对象. (判断基准:谁占主导地位),通过谁找到谁
3.多对一:多个A对象属于一个B对象,并且每个A对象只能属于一个B对象.
4.多对多:一个A对象属于多个B对象,一个B对象属于多个A对象.(老师和学生)
MyBatis一级缓存
缓存的作用/原理:
缓存本质来说就是Map,缓存是存在内存中的,可以在查询的时候减少数据库的访问次数,加快查询速度.
1.当第一次查询的时候get(1L),先将这次的调用转出一个字符串的key =Employee:1L
首先在缓存中查询是否有这个key对应的对象,如果没有,去数据库中查询.
查询之后会把该对象放入到缓存中,在把数据返回给调用者.
2.第二次查询的时候get(1L),先将这次的调用转出一个字符串的key =Employee:1L,
在缓存中查询是否有可以key对应的对象,直接从内存中的缓存获取到对应的对象,直接返回
一级缓存默认是开启的.
一级缓存生命周期==session的生命周期,在多个session中是无法进行数据共享.
在一次会话中,如果需要查询多次相同id的对象,此时后面几次的查询都会从的缓存中获取,加快了查询速度,减少了访问数据库的次数.
一级缓存的作用有限,只提高了一点点的性能.
sqlsession的缓存操作注意问题:
1: 缓存在同一个sqlsession才有效
2: 一旦sqlsession执行DML/DDL操作, 会清空缓存
3: 如果不想使用缓存,想直接从数据库获取:
可以执行: session.clearCache();
4:开发中, sqlsession缓存仅仅针对某一个session, 对于整个系统性能提升不是很高, 一般来说, 不使用. 一般会使用二级缓存.(对应SqlSessionFactory)
二级缓存
1.二级缓存生命周期==sessionFactory的生命周期.
2.二级缓存可以在不同的session之间进行数据的共享.
3.二级缓存默认是关闭的,需要手动的去开启.
4.不是所有对象都适合放到二级缓存中,只有是读远远大于写的对象才适合放到二级缓存中.
5.只要对象发生DML操作,MyBatis中的二级缓存都会给清除.
6手动开启的二级缓存.在对应的mapper.xml文件中添加一行:
一添加上就报错. java.io.NotSerializableException: cn.wolfcode._1_crud.User
要求缓存的对象需要实现序列化接口.
缓存有个策略,当内存中的对象已经达到设置的存储最大值.超出的对象如果需要也缓存起来.支持把缓存对象序列化到硬盘中.要获取的时候再反序列化回来.