Kubernetes(一)
K8S概述和特性
K8S基本介绍
K8S用于管理云平台容器化,使用K8S进行容器化部署.
K8S有利于应用扩展.
K8S的目标实施让部署容器化应用更加简洁和高效.
K8S功能
自动装箱
基于容器对应用运行环境的资源配置要求,自动部署应用容器.
自我修复
当容器失败时,会对容器进行重新部署和重新调度.
当容器未通过检查的时候,会关闭此容器,直到容器正常运行的时候才会对外开放服务.
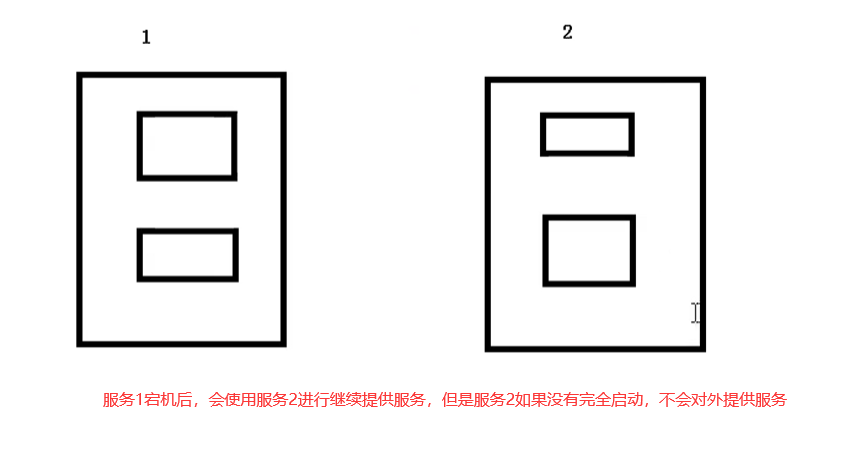
如果某个服务器上的应用不响应了.K8S会自动在其他地方创建一个
水平扩展
通过简单的命令、用户UI界面或基于CPU等资源的使用情况,对容器应用进行规模扩大或者规模裁剪
需要处理大量的请求,可以通过增加副本的数量,从而达到水平扩展的效果.
服务发现
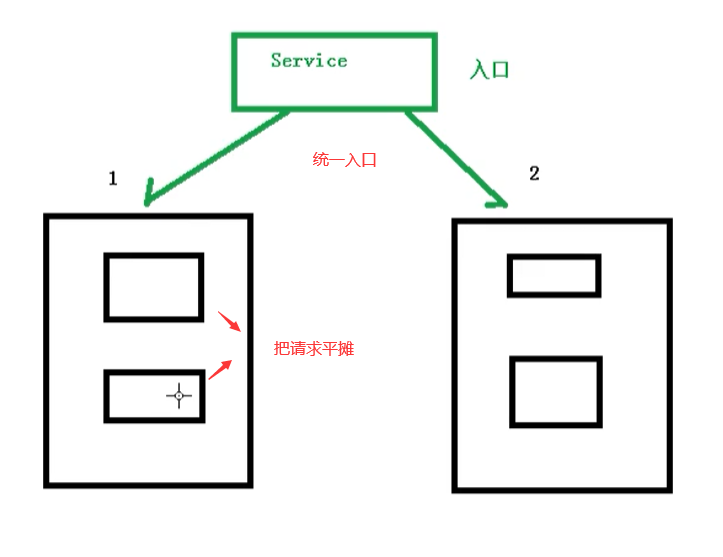
K8S不需要额外的服务发现机制(eureka、nacos).基于自身的能力实现 服务发现 和 负载均衡
对外提供统一的入口,让它来做节点的调度和负载均衡,相当于 微服务里面的 网关.
滚动更新
可以根据应用的变化,对应容器运行的应用,进行一次性或批量式的更新
在添加应用的时候不是马上启用,而要先去判断新增的应用是否能够正常使用
版本回退
可以根据应用部署的情况,对应用容器运行的应用,进行历史版本的回退.
类似Git的回滚
密钥和配置管理
在不需要构建新镜像的情况下,可以部署和更新密钥应用配置,类似热部署.
存储编排
自动实现存储系统的挂载和应用.对有状态的应用实现数据持久化非常重要.
存储系统可以来自于本地目录、网络存储(NFS)、公共云储存服务.
批量处理
提供一次性任务,定时任务.满足批量数据处理和分析的场景.
K8S架构组件
完整架构图
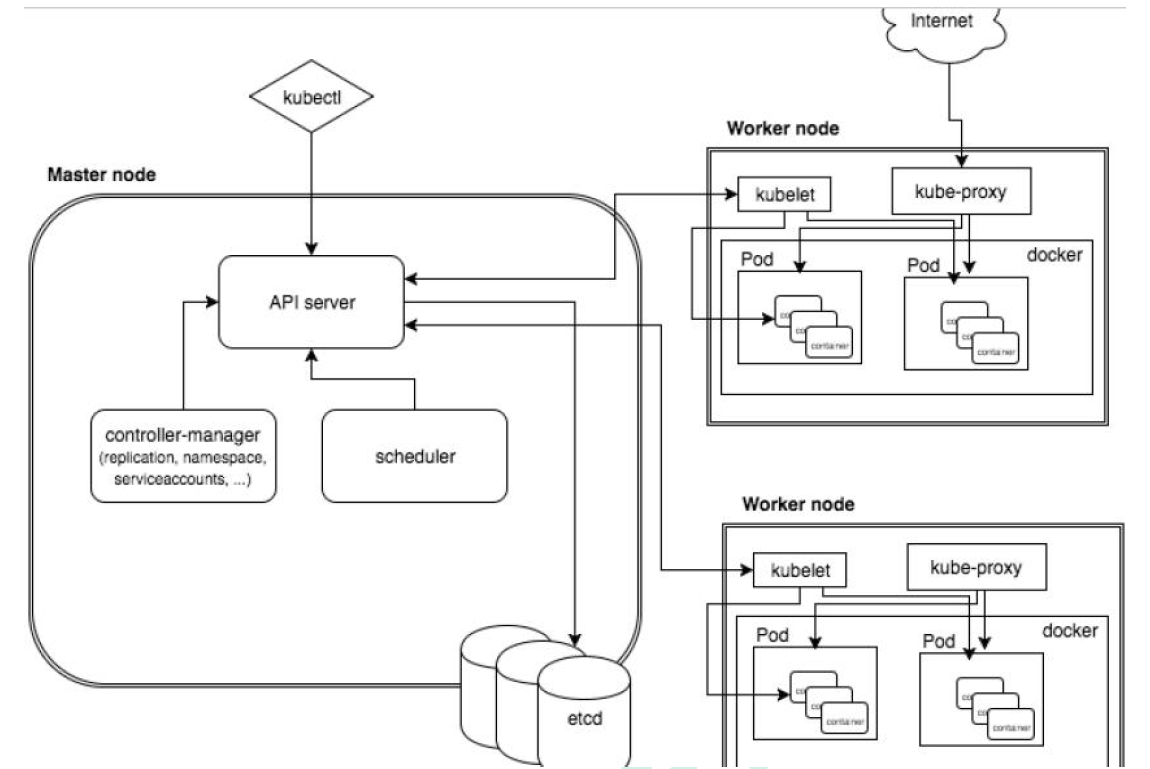
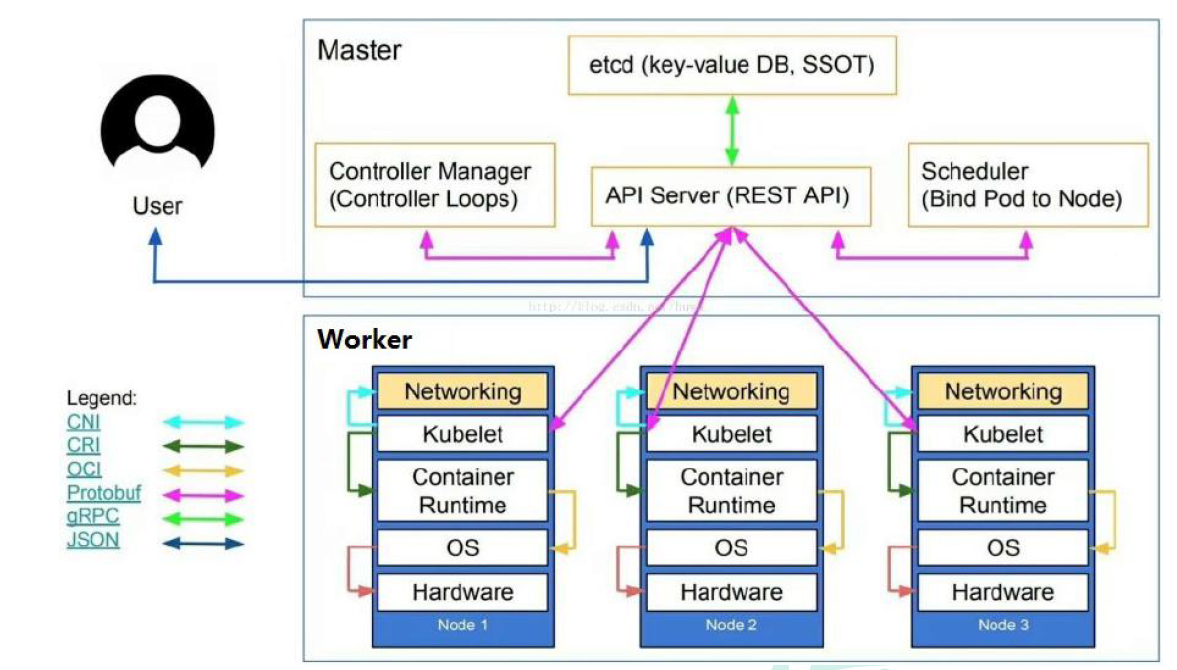
架构细节
K8S架构主要包含两部分: master(主控节点) 和 node(工作节点)
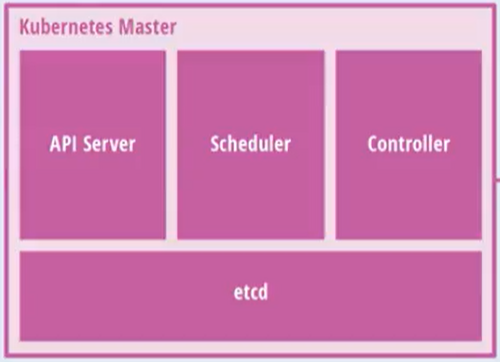
master节点架构图
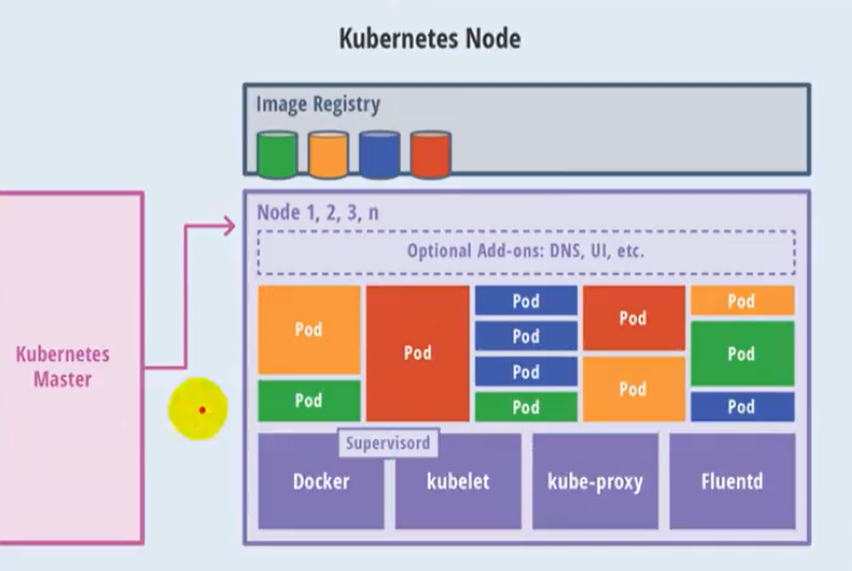
Node节点架构图
K8S集群控制节点,对集群进行调度管理.接受集群外用户去集群操作请求.
- maser:主控节点
- API Server:集群统一入口,以restful风格进行操作,同时交给etcd存储
- 提供认证、授权、访问控制、API注册和发现等机制
- scheduler:节点的调度,选择node节点应用部署
- controller-manager:处理集群中常规后台任务,一个资源对应一个控制器.
- etcd:存储系统,用于保存集群中的相关数据.
- API Server:集群统一入口,以restful风格进行操作,同时交给etcd存储
- work node:工作节点
- kubelet: master派到node节点的代表,管理本机容器.
- 一个集群中每个节点上运行的代理,它保证容器都运行在Pod中
- 负责维护容器的生命周期,同时也负责Volume(CSI)和网络(CNI)的管理
- kube-proxy:提供网络代理,负载均衡等操作.
- kubelet: master派到node节点的代表,管理本机容器.
- 容器运行环境[container runtime]
- 容器运行环境是负责运行容器的软件
- K8S支持多个容器运行环境:Docker、container、cri-o、rktlet以及任何实现kubernetes CRI(容器运行环境接口)的软件.
- fluentd:是一个守护进程,有助于提升 集群层面日志
K8S核心概念
Pod
- Pod是K8S中最小的单元.
- 一组容器的集合
- 共享网络[一个Pod中的所有容器共享同一个网络]
- 生命周期是短暂的(服务重启后,找不到了)
Volume
- 声明在Pod容器中可以访问的文件目录
- 可以被挂载到Pod中的一个或多个容器指定路径下
- 支持多种后端存储抽象[本地存储、分布式存储、云存储]
Controller
- 确保预期的pod副本数量 [ReplicaSet]
- 无状态应用部署 [Depoltment]
- 无状态是指,不需要依赖于网络或者ip
- 有状态应用部署[StatefulSet]
- 有状态需要特定的条件
- 确保所有的node运行同一个pod [DaemonSet]
- 一次性任务和定时任务 [Job和CronJob]
Deployment
- 定义一组Pod副本数目、版本等
- 通过控制器[Controller] 维持Pod数目 [自动恢复失败的Pod]
- 通过控制器以指定的策略控制版本 [滚动升级、回滚等]
Service
定义一组pod的访问规则
pod的负载均衡,提供一个或多个pod的稳定访问地址
支持多种方式 [ClusterIP、NodePort、LoadBalancer]
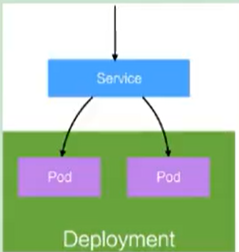
可以用来组合pod,同时对外提供服务.
label
label: 标签,用于对象资源查询,筛选

Namespace
命名空间,逻辑隔离
- 一个集群内部的逻辑隔离机制 [鉴权、资源]
- 每个资源都属于一个namespace
- 同一个namespace所有资源不能重复
- 不同的namespace可以资源名重复
API
我们通过K8S的API来操作整个集群
同时我们可以通过kubectl、ui、curl最终发送http + json/yaml 方式的请求给API Server,然后控制整个K8S集群,K8S中所有的资源对象都可以采用 yaml 或 json 格式的文件定义或描述.
例: 使用yaml部署一个nginx的pod

完整流程
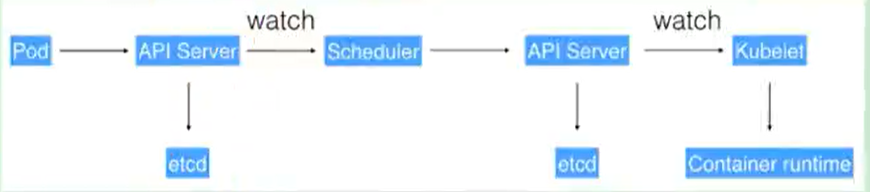
通过kubectl提交一个创建RC(Replication Controller) 的请求,该请求通过APIserver写入etcd
此时controller manager 通过API Server的监听资源变化的接口监听到此RC事件
分析之后,发现当前集群中还没有它所对应的pod实例
于是根据RC里的Pod模板定义一个生产Pod对象,通过APIServer写入etcd
此事件被scheduler发现,它立即执行一个复杂的调度流程,为这个新的Pod选定一个落户的Node,然后通过API Server将这一结果写入到etcd中.
目标Node上运行的kubelet进程通过API Server监测到这个“新的Pod”,并按照它的定义,启动该pod并负责到底,直到这个Pod的生命周期结束.
随后,我们通过kubectl提交一个新的映射到该Pod的Service的创建请求
ControllerManager通过Label标签查询到关联的Pod实例,然后生成service的endpoints信息,并通过APIServer写入到etcd中.
接下来,所有node上运行的proxy进程通过APIserver查询并监听service对象与其对应的endpoints信息,建立一个软件方式的负载均衡器来实现service访问到后端Pod的流量转发功能.
核心技术Pod
Pod概述
pod是K8S可以创建和管理的最小单元,是资源对象模型中由用户创建或部署的最小资源对象模型,也是在K8S上运行容器化应用的资源对象,其他的资源对象都是用来支撑或者扩展Pod对象功能的.
比如:
控制器对象 是用来管理Pod对象的.
Service或者ingress资源对象 是用来暴露Pod引用对象的.
PersistentVolume资源对象 是用来为Pod 提供存储的
K8S不会直接处理容器,而是通过Pod.Pod 是由一个或者多个容器组成的.
Pod是K8S最重要的概念,每个Pod都有一个特殊的被称为“根容器”的pause容器.
pause容器对应的镜像属于K8S平台的一部分,除了pause容器,每个pod还包含一个或者多个紧密相关的用户业务容器.
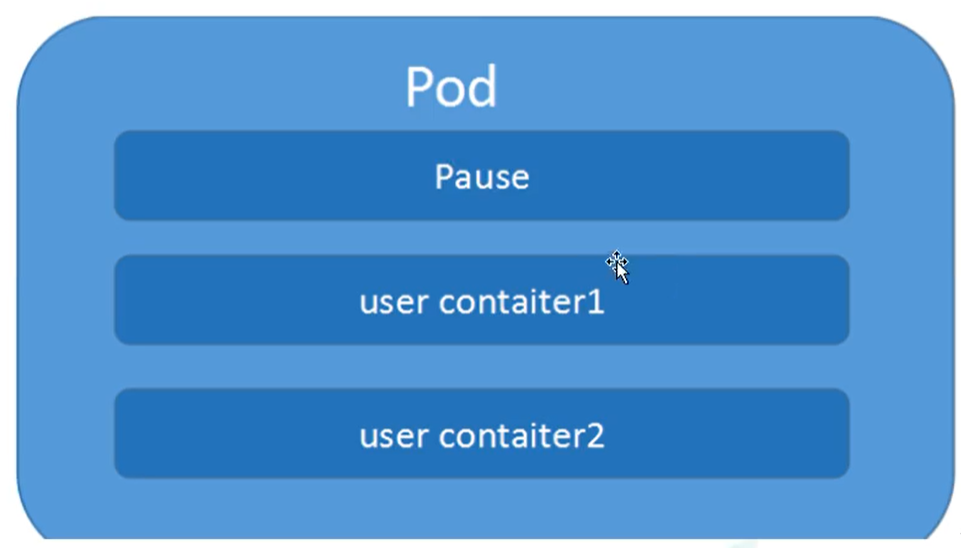
Pod的基本概念
- 最小的部署单元
- Pod里面由一个或者多个容器组成[一组容器的集合]
- 一个Pod中的容器 是共享网络 命名空间
- Pod是 短暂的
- 每个Pod包含一个或多个紧密相关的用户业务容器
Pod存在的意义
- 创建容器使用的是docker,一个docker对应一个容器,一个容器运行一个应用进程.
- Pod是多进程设计,运用多个应用程序,也就是一个Pod里面有多个容器,而一个容器里面运行一个应用程序.
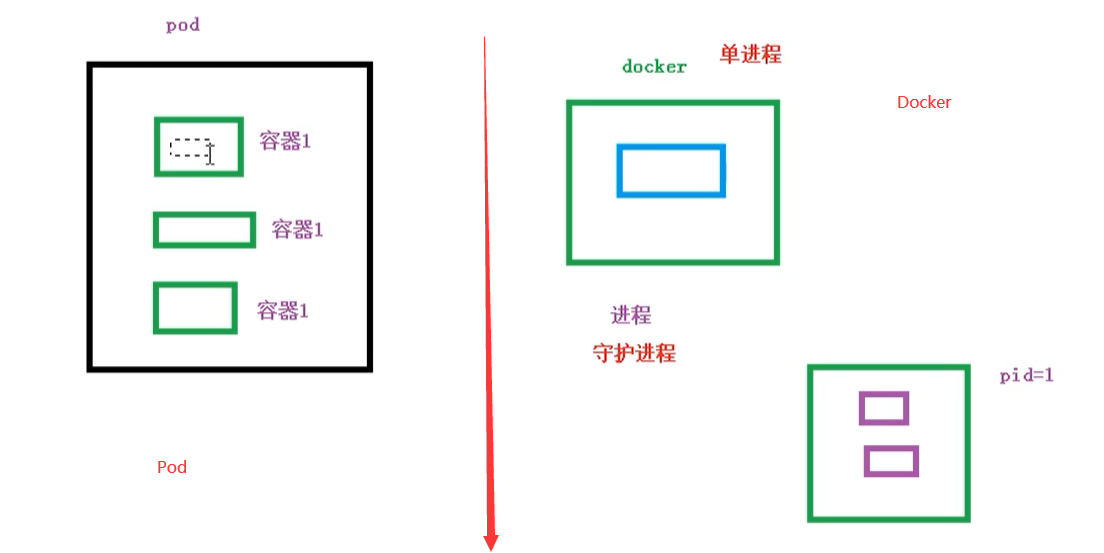
- Pod的存在就是为了亲密性应用.
- 两个应用进行交互
- 两个网络之间调用 [通过127.0.0.1 或者 socket]
- 两个应用之间需要频繁调用
Pod是在K8S集群中运行部署应用或服务的最小单元,它是可以支持多容器的.Pod的设计理念是支持多个容器在Pod中共享 网络 和文件系统,可以通过 进程通信 和 文件共享这种简单高效的方式组合完成服务.同时Pod对多容器的支持是K8S中最基础的设计理念.
在生产环境中,通常各自开发构建自己的 容器镜像,在部署的时候组合成一个微服务对外提供服务.
Pod是K8S集群中所有业务类型的基础,可以把pod看作是运行在K8S上集群的小机器人,不同类型的业务就需要不同类型的小机器人去执行.
目前K8S的业务可以分为以下几种
- 长期伺服型: long-running
- 批处理型: batch
- 节点后台支撑型: node-daemon
- 有状态应用型: stateful application
上述几种类型,分别对应小机器人控制器为: deployment、job、daemonSet和statefulSet
Pod的实现机制
主要有两大机制
网络共享
文件存储
共享网络
容器之间是互相隔离的,一般是通过 namespace 和 group 进行隔离,Pod里面的容器如何实现通信?
首先需要满足在同一个 namespace 之间
关于Pod的实现原理,首先会在Pod中创建一个根容器:pause容器.
然后在我们创建业务容器 [nginx和redis] 的时候,会把它添加到 info 容器中.
而在 info容器中 会独立 ip地址、mac地址、prot信息.然后实现网络共享.
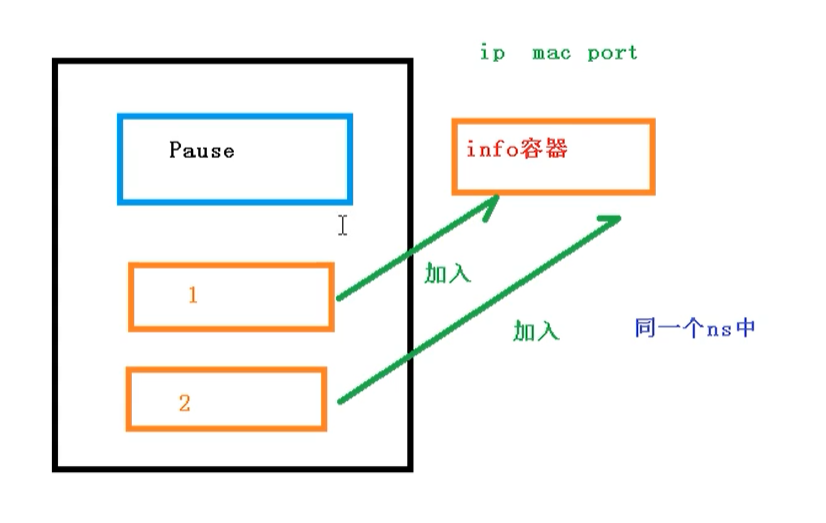
同pause容器,把其他业务容器加入到 info 容器中,让所有业务容器在同一个命名空间中,实现网络共享.
共享存储
Pod持久化数据,专门存储到某个地方中.
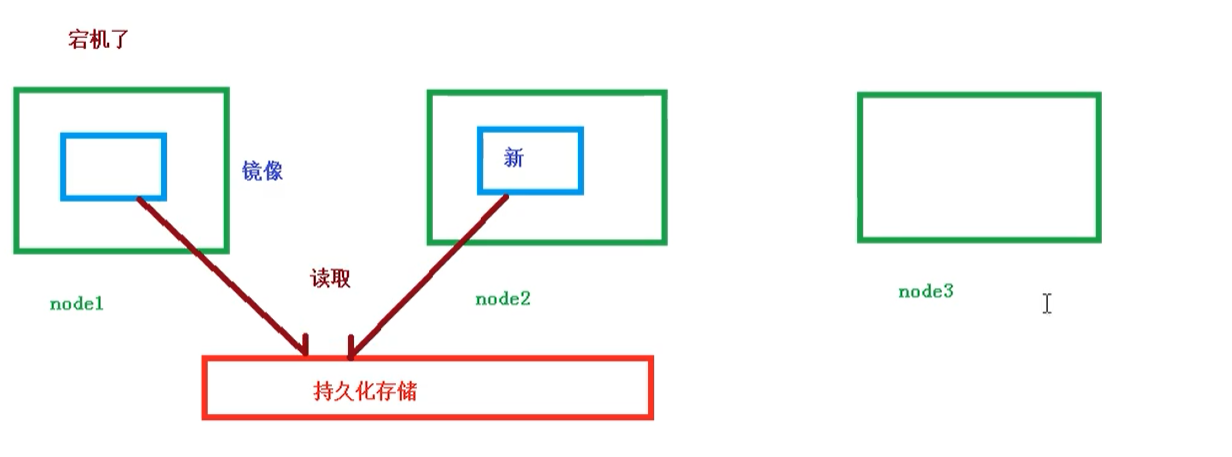
使用 volume 容器数据卷进行共享储存

Pod镜像拉取策略
拉取策略就是 imagePullPolicy

拉取策略主要分为几种:
IfNotPresent: 默认值,镜像在宿主机上 不存在,才拉取.Always: 每次创建Pod都会重新拉取一次镜像.Never: Pod永远不会主动拉取这个镜像.
Pod资源限制
也就是我们Pod在进行调度的时候,可以对调度的资源进行限制.例如我们限制Pod调度的资源是2c4g,那么在调度对应的node节点时,只会占用对应的资源.对于不满足资源的节点,将不会进行调度.
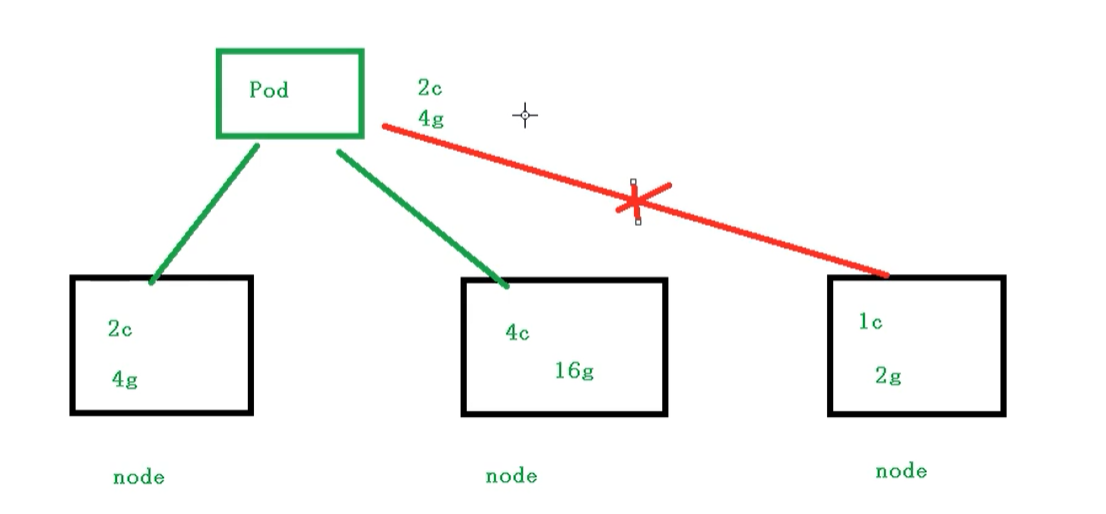
资源限制:
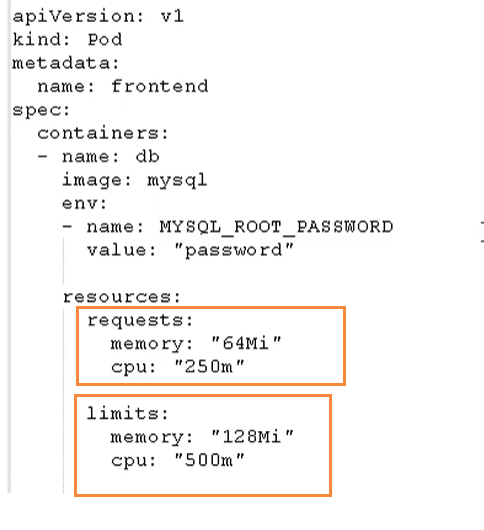
这里分了两个部分.
- request: 表示调度所需要的资源
- limits: 表示最大所占用的资源
Pod重启机制
因为Pod包含了很多个容器,假设某个容器出现问题了,那么会触发Pod重启机制.
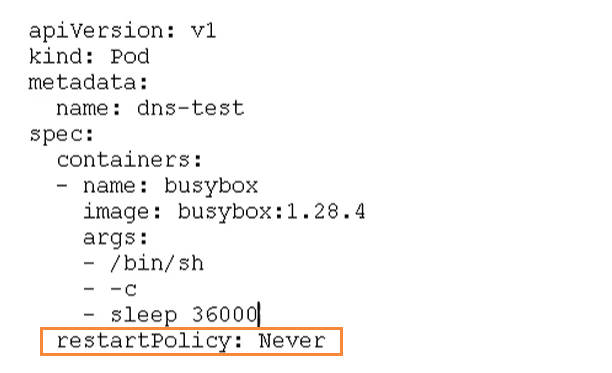
重启策略主要分为3种:
Always: 当容器重启退出后,总是重启容器,默认策略.[nginx等,需要不断提供服务]OnFailure: 当容器异常退出(退出状态码 !0)时,才重启容器.Never: 当容器终止退出时,从不重启容器.[批量任务]
Pod健康检查
通过容器检查,原来我们使用下面的命令来检查
kubectl get pod
但是有的时候,程序可能出现了java堆栈内存溢出,程序还在运行,但是不能对外提供服务了.这个时候不能通过容器检查来判断服务是否可用.
使用应用层面的检查
1 | 存活检查,如果检查失败,将杀死容器.根据pod的restartPolicy[重启策略]来操作 |

Probe支持以下三种检查方式
- http Get: 发送http请求,返回200 - 400范围的状态码为成功.
- exec: 执行shell命令状态码返回是0为成功.
- tcpSocket:发起TCP Socket建立成功
Pod调度策略
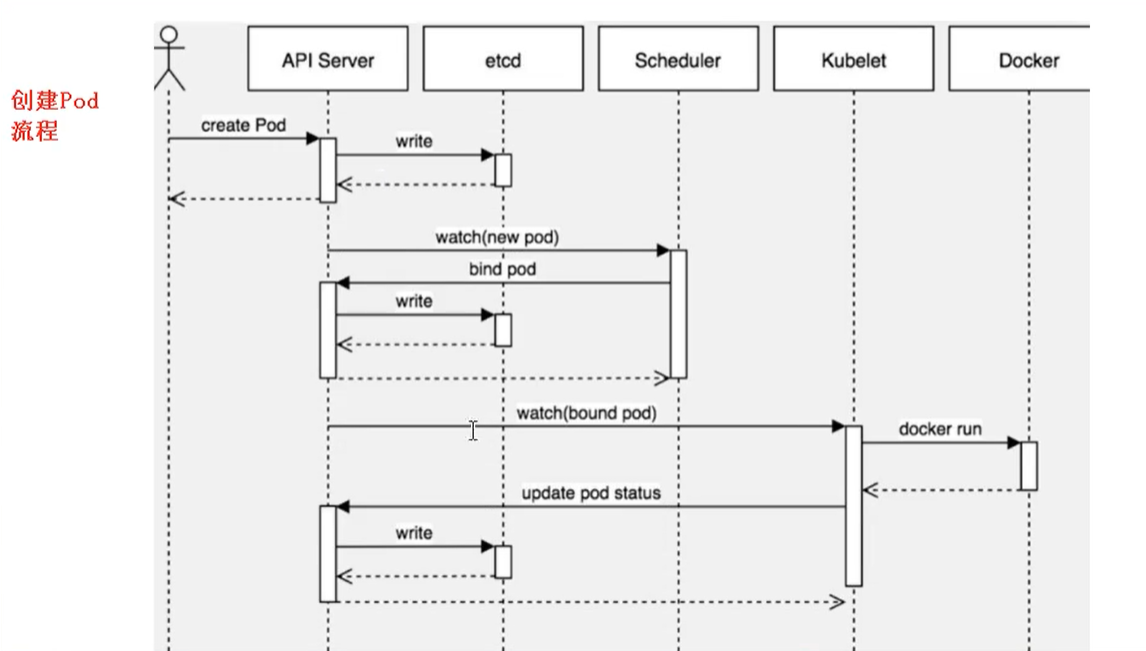
创建Pod流程
- 首先创建一个Pod,然后创建一个API Server 和 Etcd[把创建出来的信息储存在Etcd中]
- 然后创建 Scheduler,监控API Server是否有新的Pod.如果有的话,会通过调度算法,把Pod调度到某个node上.
- 在node节点,会通过
kubelet --apiserver读取etcd 拿到分配在当前node节点上的pod,然后通过docker创建容器.
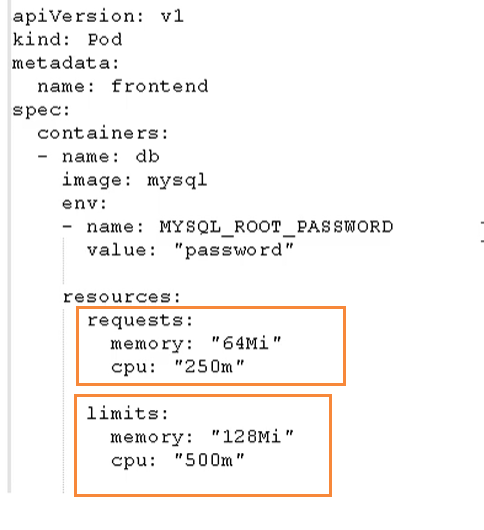
影响Pod调度的属性
Pod资源限制会对Pod的调度有影响.
根据request找到足够的node节点进行调度
节点选择器标签影响pod调度

关于节点选择器,其实就是有两个环境,然后环境之间所用的配置资源不同.
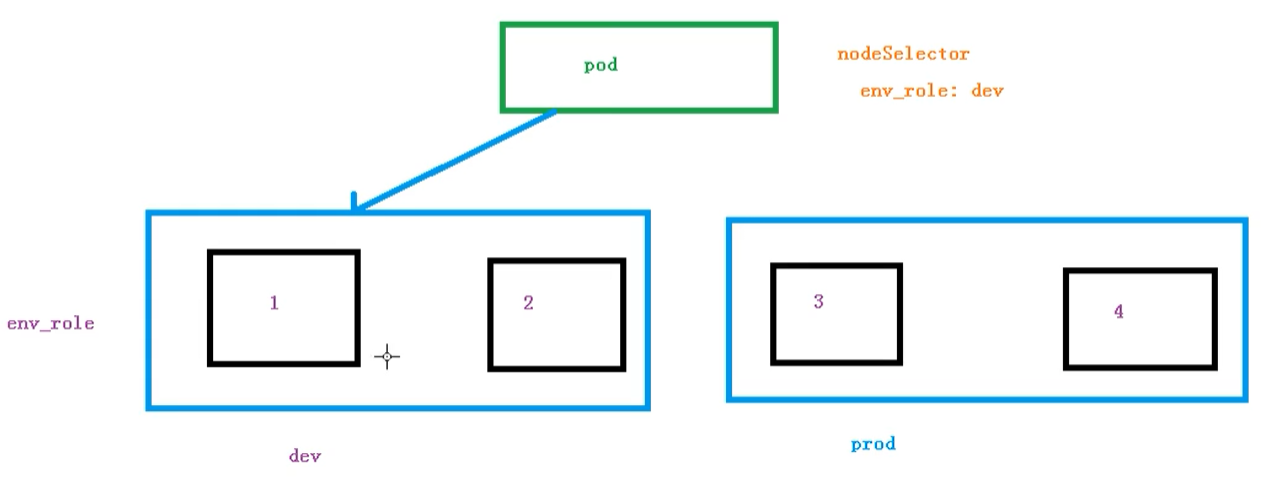
我们可以通过以下命令,给节点新增标签,然后节点选择器就会根据标签进行调度
1 | kubectl label node node1 env_role=prod |
节点亲和性
节点亲和性 nodeAffinity和 之前的nodeSelector基本一样,根据节点上的标签约束来决定Pod调度到哪个节点上.
- 硬亲和性: 约束条件必须满足
- 软亲和性: 尝试满足,不保证

支持常用操作符: in、NotIn、Gt、Lt、DoesNotExists
反亲和性:就是和亲和性刚刚相反.如 NotIn、DoesNotExists等
污点和污点容忍
概述
nodeSelector 和 NodeAffinity,都是prod调度到某个节点上的,属于pod属性,是在调度的时候实现的.
Taint污点:节点不做普通分配调度,是节点属性.
场景
专用节点[限制ip]
配置特定硬件的节点[固态硬盘]
基于Taint驱逐[在node1不放,在node2放]
查看污点情况
1 | kubectl describe node k8smaster | grep Taint |
污点值有三个
- NoSchedule: 一定不被调度.
- PreferNoSchedule: 尽量不被调度.
- NoExecute: 不会调度,并且还会驱逐node已有的Pod
末节点添加污点
1 | kubectl taint node [node] key=value:污点的三个值 |
例如:
1 | kubectl taint node k8snode1 env_role=yes:NoSchedule |
删除污点
1 | kubectl taint node k8snode1 env_role:NoSchedule- |
污点容忍
污点容忍就是某个node可能被调度也可能不被调度.